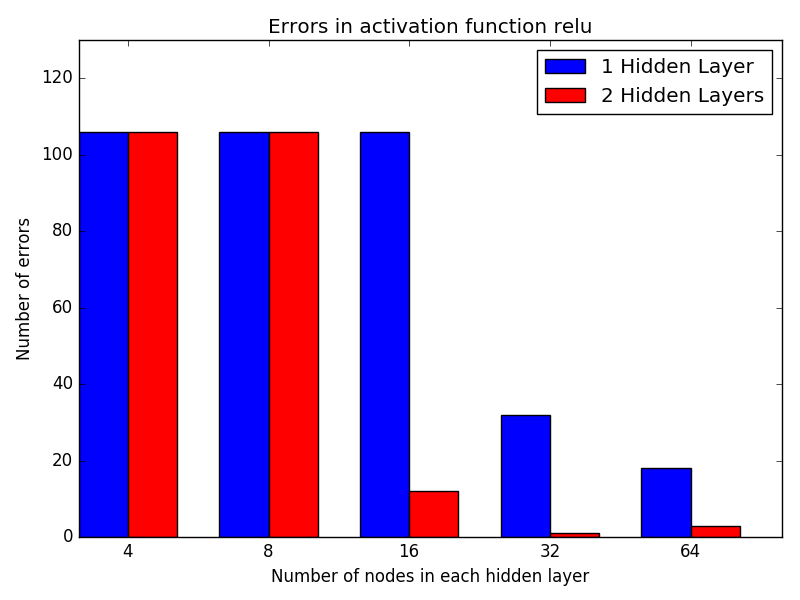
For testing, two texts were used. The first was Leo Tolstoy's War and Peace, which has minimal markup characters. The other text was the source code for the Linux Kernel, which uses markup characters extensively. Some generalized findings are that LSTM and Gated Recurrent Unit (GRU) models work much better than a simple RNN. The models work better with 2 hidden layers rather than 1, and for the GRU, a third layer can sometimes see additional benefit. I find it surprising that more than 2 hidden layers seems to increase the LSTM cross entropy (although only slightly).

This figure from the paper shows the activity of cells in the best LSTMs. Text color corresponds to tanh(c), where -1 is red and +1 is blue. The first cell is sensitive to the position in a line. In a sense, it is counting how many characters are in the line. Some cells can very clearly activate inside of quotes, if statements, comments, or for predicting new lines. This shows how some cells are highly-specialized into niches.


This figure shows how LSTMs are able to consistently outperform 20-gram models in matching a closing bracket with the corresponding opening bracket. This provides strong evidence that they are able to keep track of long-range interactions. The LSTM shows improvement up to a distance of about 60 characters, then it has difficulty keeping track of the long-range dependencies, though it still performs well.

This last figure shows the breakdown of types of errors that the LSTM made. This was done by, as they say in the paper, "peeling the onion". They start by peeling away errors at the top of the pie chart and go counterclockwise around. They remove the errors by using a particular model and count how many there are. Errors are defined to occur when the probability a character is assigned is below 0.5.
They start by using an n-gram model that might be better at short-term dependencies. The character error is removed if the n-gram assigns more than 0.5 probability to the new character assignment.
The n memory model eliminates instances where the LSTM makes the same error with a substring in the past n characters. The LSTM consistently makes these errors, despite the theoretical possibility that it could learn correctly after training on the first substring.
Rare words present a problem because the LSTM might not have had enough opportunities to train on them to give a correct answer. This can be corrected by a larger training set or better pretraining. These are removed and the error is presented based on how frequently that word occured in the training set.
Many of the errors occurred after a space or a quote, after a newline (which the LSTM needs to learn acts the same as a space), or after punctuation. The remaining errors did not have apparent structures and were removed by simply adding 0.1,0.2,0.3,0.4, or 0.5 to the probability of that character until all errors were accounted for.
Interestingly, increasing the number of layers and nodes of the LSTM had a dramatic improvement in correcting for n-gram errors, but other types of errors seemed to be unaffected. It is expeced that further scaling up the model even larger will eliminate n-gram errors, but to fix other errors, different architecture may be required.
----------
Link to the paper