I tested using several different activation functions, and here is what I've found:
Wrong Approach
First, I defined errors the number of errors to be:
nb_errors=abs(sum(y1-Y_test)) ,
where y1 is the output of the neural network, and Y_test is the actual results from the dataset.
This is the wrong approach because it means that false positives make my data look better. If the network detects outputs a '1' where there should be a '0', then that will effectively cancel out some of the false negatives, where the network outputs a '0', but there should be a '1'. This resulted in some interesting behavior.
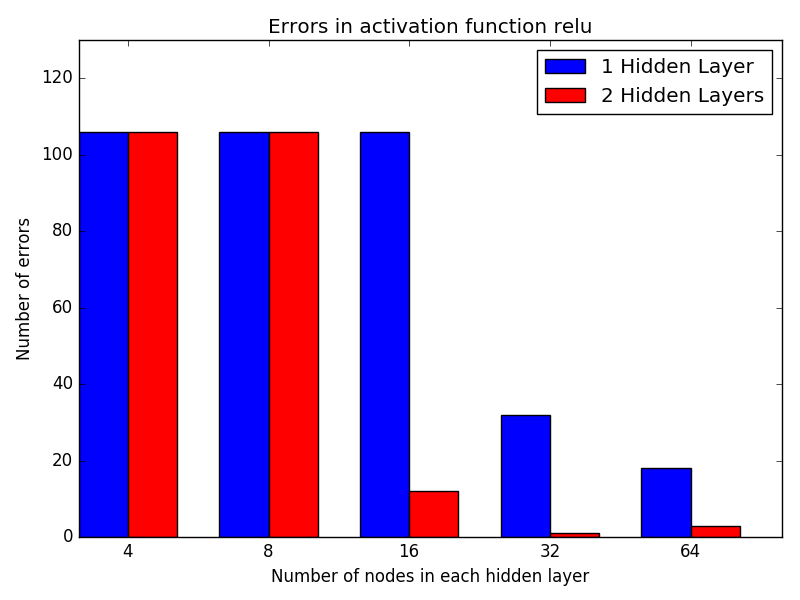

With only 1 hidden layer, both networks performed much worse than with 2, even when the number of nodes were the same. The number of errors saturate when there is few nodes with the 'relu' activation function, because the network is outputting an answer of all-zeros. For these instances. it hasn't really learned anything yet, but it gets an answer that still get ~85% of the outputs right.
More interesting is the performance of 'tanh'. It actually does better with fewer nodes so long as there are two hidden layers. This is because 'tanh' seems to give more false positives than 'relu' for this dataset.
Right Approach
The number of errors should be calculated by:nb_errors=sum(abs(y1-Y_test)) ,
This way, the false positives and false negatives are treated the same, so you can get the total number of errors by just adding them up. Here is the results from this approach:



I also tested the 'sigmoid' activation function, and it performed poorly. It was not able to break away from the answer of all-zeros until the very end of the last simulation, and even then it performed poorly. Thus, Sigmoid does not appear to be a good activation function to use for the hidden layers.
Conclusion
'tanh' performs better than 'relu' for this binary classification problem. It also has a higher frequency of false-positives. This is fine for the lending industry, which may be hesitant to give out risky loans, but if false-positives are worse than false-negatives, than the 'relu' activation function may be better to use so long as enough nodes are used to get a good answer.
---------------------------download the data set: creditset.csv
download my: python code
No comments:
Post a Comment